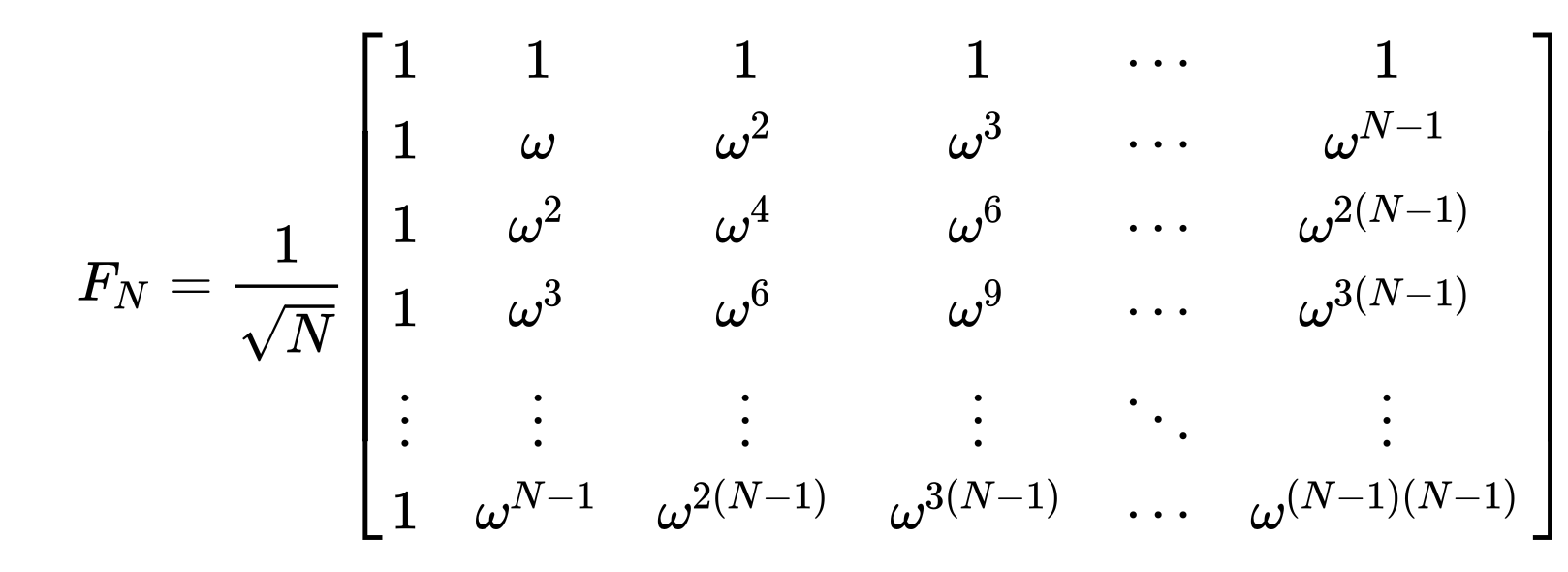This post aims to cover some practical aspects of post-quantum cryptography and homomorphic encryption, topics I’ve been interested in over the past few months. Much of this work was performed during a Cryptography Fellowship with Zaiku Group, Ltd.
These tools are meant to provide modern upgrades to some current cryptographic schemes which have been in use for decades. Namely, RSA (Rivest, Shamir, Adleman) and elliptic curve cryptography (ECDH, ECIES, ECDSA). These two approaches are related to each other in that they can both be phrased as discrete logarithm problems, though on different groups. For RSA, the group is the multiplicative group of the integers mod $p$, $(Z_p)^{\times}$ for a prime $p$. For elliptic curves, we use the analogous group $E(F_p)$, the $F_p$-points of the curve E over a finite field $F_p$.
RSA was introduced in 1977 and published in 1978: “A Method for Obtaining Digital Signatures and Public-Key Cryptosystems”; by Ronald L. Rivest, Adi Shamir, and Leonard M. Adleman in the journal Communications of the ACM (Volume 21, Issue 2). The basic layout of RSA is as follows:
RSA is a public-key cryptosystem based on the hardness of factoring large integers.
Key generation: Choose two large primes $p$ and $q$. Compute $n = pq$ and $\varphi(n) = (p-1)(q-1)$. Pick a public exponent $e$, then compute the private exponent $d$ such that $ed \equiv 1 \text{ mod } \varphi(n)$.
Public key: $(n, e)$
Private key: $d$
Encryption: $c = m^e \text{ mod } n$
Decryption: $m = c^d \text{ mod } n$
Security relies on the difficulty of factoring $n$. If one factors $n$, then one can compute the totient $\varphi(n)$, and then compute the modular inverse $d =e^{-1} \text{ mod } \varphi(n)$.
RSA was first standardized by NIST in 1993 as part of the Digital Signature Standard (DSS) family, specifically in FIPS 186-1, which included RSA as an approved algorithm for digital signatures.
There is a quantum algorithm which can be used to break RSA known as Shor’s algorithm. This algorithm makes use of the fact that $a^x \text{ mod } n$ is a periodic function on $(Z/nZ)^{\times}$. If one is able to find the period $ r$ so that $a^r \equiv 1 \text{ mod } n$, then note $(a^{r/2} – 1)(a^{r/2} + 1) \equiv 0 \text{ mod } n $, so $gcd(a^{r/2} – 1, a^{r/2} + 1)$ is likely to be a factor.
In order to extract the period, the function is essentially spread in an unobservered superposition across the entire (exponential) set of integers $x$ from $0$ to $2^n-1$, and the exponentials computed via controlled modular exponentiation. Then the iQFT (inverse quantum Fourier transform) is applied to this overall state. The QFT is fast, in that it runs in $O(n\log(n))$ time despite operating on $2^n$ states, since it can operate on tensor products of $n$ qubits. This allows efficient and polynomial time extraction of the period $r$ after a quick classical computation via continued fractions to get the actual factors.
This algorithm was discovered by Peter W. Shor: “Algorithms for quantum computation: discrete logarithms and factoring”, Presented at the 35th Annual Symposium on Foundations of Computer Science (FOCS) in 1994.
For elliptic curves, we take a plane curve $E: y^2 = x^3 + Ax + B$ over a finite field $F_p$, whose points form an abelian group. Choose a base point $P$. Alice picks a secret number a, and lets $P_0 = aP$ (add $P$ to itself $a$ times ), her public key. Bob picks a secret number $b$ and computes $P_1 = bP$, his public key. For the key exchange, Alice computes $aP_1 = abP$ and Bob computes $bP_0 = abP$, so they get the same point on the curve, which can be used to derive a shared key. Note that given $(aP, P)$ it is very difficult to determine $a$. This is known as the elliptic curve discrete logarithm problem (ECDLP), and is analogous to RSA where here we are using the addition in the elliptic curve group $E(F_p)$.
The key sizes for elliptic curves are much smaller than RSA (256 bit ECC ~ 3072 bit RSA).
A variant of Shor’s algorithm which still performs Fourier sampling just over the abelian group of the elliptic curve $E(F_p)$ rather than the multiplicative group of integers mod $n$. Thus, this is an effective attack on the ECDLP.
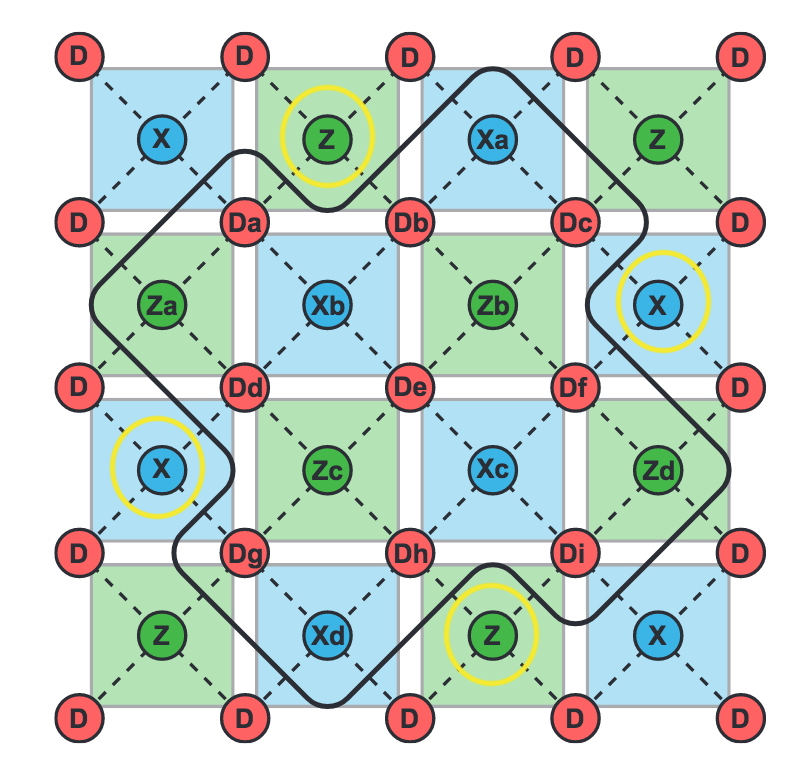
There is a lot of current discussion re: when quantum computers will become reliable, fault-tolerant, error corrected, and large enough to perform useful computation. Currently there are 127 qubit systems available publicly via IBM. Google also has similar sized machines. The best error correction codes appear to be surface codes, with a $d \times d$ array with $d=7$ qubits, and then hundreds or thousands of physical qubits per logical qubit. This allows the correction of up to 3 errors.
In general, it may take awhile before there are thousands of qubits required to break something like RSA-1024, which would mean factoring a 1024-bit integer. Estimates range, but something like 5-10 years seems plausible, especially given the exponential nature of progress with respect to number of qubits. To that end, NIST has stated that cryptographic schemes like RSA and ECC with 128 bit security levels will be deprecated by Dec. 31st 2030, and no longer allowed by Dec. 31st 2035. This means that the transition to post-quantum cryptography has already begun, and will probably accelerate over the next five years with many systems being replaced.
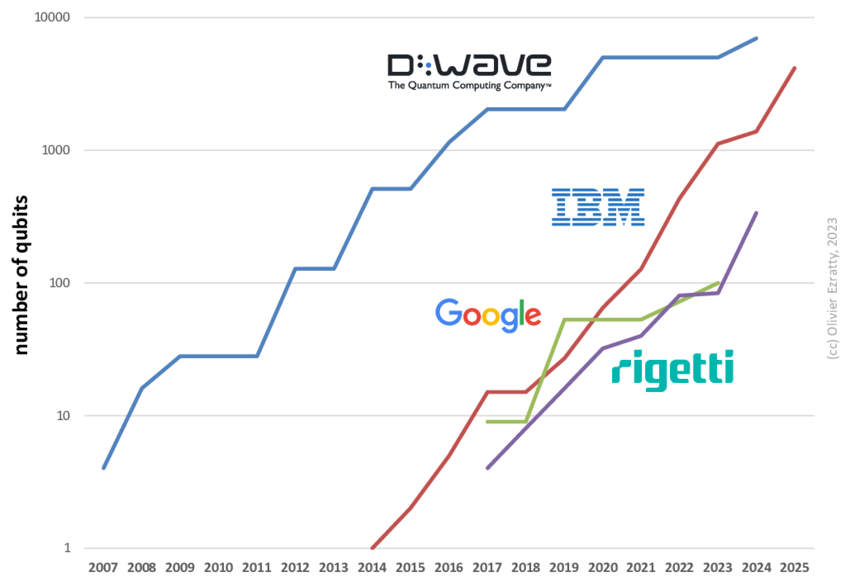
NIST, Transition to Post-Quantum Cryptography Standards:
https://csrc.nist.gov/pubs/ir/8547/ipd
There is a major issue in the meantime that encrypted data that is collected (“harvested”) now will be able to be decrypted later by sufficiently large quantum computers later (“harvest now, decrypt later”). Therefore it is crucial that these systems and databases are replaced as soon as possible.
To this end, NIST ran a competition to determine the best among a selection of competing post-quantum cryptography standards.
https://csrc.nist.gov/projects/post-quantum-cryptography/post-quantum-cryptography-standardization
In the end, the three winners were: CRYSTALS-Dilithium, CRYSTALS-KYBER and SPHINCS+, from which FIPS 203, FIPS 204, and FIPS 205 are respectively derived.
- Crystals-Dilithium is a digital signature scheme, used for signing and verification. It is based on lattice problems like module-LWE and module-SIS.
- CRYSTALS-KYBER is a key encapsulation mechanism, used for generating and encrypting a shared symmetric key to be used with another symmetric key encryption scheme. These are based on lattice problems like module-LWE.
- SPHINCS+ is a stateless hash-based digital signature scheme — meaning it relies purely on hash functions (like SHA-256) for its security, rather than number-theoretic problems or lattices.
We’ll primarily focus on lattice-based cryptography methods in this post. These are cryptosystems based on algebraic lattices which are very similar to rings of integers in algebraic number fields (like the cyclotomic integers $\mathbb{Z}[x]/(x^n-1)$, but using $x^n+1$ instead, and working over $\mathbb{Z}_q$ rather than $\mathbb{Z}$).
Each system is based on a computationally hard problem that currently does not have a polynomial time quantum algorithm to solve it. We’ll go into more detail later, but examples of these problems are:
- Learning with errors (LWE): Given a set of noisy linear equations, find the secret vector. In mathematical terms, you’re given a set of noisy linear combinations of a secret vector, and the task is to recover the secret vector despite the noise.
- Shortest vector problem (SVP): Given a lattice, find the shortest non-zero vector in that lattice. This is known to be a hard problem in general lattices, and it’s often used as the foundation for other cryptographic protocols. The hardness arises when the given basis is not orthogonal.
- Closest vector problem (CVP): Given a lattice and a target point, find the closest lattice point to that target. In cryptographic settings, this is used for things like encryption or key exchange protocols.
- ring-LWE: This is a specialized version of LWE, where the secret and error terms live in a ring structure, which makes the problem more efficient but still computationally hard.
- module-LWE: Similar to Ring-LWE, but operates in a module setting, which generalizes the ring structure to a rank $k$ module over the ring.
In this post, we’ll primarily focus on ring-LWE, module-LWE, and FIPS 203.
FIPS 203 is the module-lattice key encapsulation mechanism (ML-KEM) derived from CRYSTALS-Kyber. It does use module-LWE under the hood in the internal PKE (public key encryption) portion, which we’ll cover in detail later.
We’ll begin with ring-LWE, a post-quantum fully homomorphic encryption scheme.
ring-LWE, homomorphic encryption
- slides: ring_lwe.pdf
- code:https://crates.io/crates/ring-lwe
For modern cryptography, we aim to find problems that are impractical or ideally impossible to solve, even on a quantum computer.
The “learning with errors” (LWE) problem, along with its ring-LWE variant, are examples of such problems. It involves distinguishing between two distributions:
- A set of random linear equations perturbed by a small error (noise)
- A truly uniform random distribution
Given $(\bf{A}, \bf{b}) \in \mathbb{Z}_q^{n \times m} \times \mathbb{Z}_q^m$ where $\bf{b} = \bf{A}\bf{s} + \bf{e} \text{ mod } q$:
- $\bf{A}$ is a known random matrix
- $\bf{s}$ is a secret vector
- $\bf{e}$ is a noise vector sampled from a narrow error distribution
- $q$ is a large modulus
The goal is to recover the secret $\bf{s}$ or distinguish $(\bf{A},\bf{b})$ from uniformly random samples.
We’d like to ensure that instances of LWE are hard in the average case. This is done by proving reductions from well-known hard problems in computer science:
- $\bf{GapSVP}$: Shortest vector problem with a gap
- $\bf{SIVP}$: Shortest independent vector problem
These lattice problems are:
- NP-hard in their exact versions
- Computationally hard in their approximate versions
The variant we focus on is ring-LWE, where the lattices are number-theoretic and derived from ideals in certain polynomial rings:
$R_q = \mathbb{Z}_q[x]/(f(x))$
where $f(x)$ is typically a polynomial like $x^n – 1$. However, this choice is insecure. Instead, we use:
$f(x) = x^n+1$
where $n$ is a power of two. This is the “anti-cyclotomic” ring of integers.
The hard problem becomes:
- $\bf{Ideal-SVP}$: Shortest vector problem for ideal lattices
Consider the ring $R = \mathbb{Z}[x]/(x^n + 1)$:
- This is a $\mathbb{Z}$-module of rank $n$.
- Any element $a(x) \in R$ can be written as: $a(x) = \sum_{i=0}^{n-1} c_i x^i$
- The vector $(c_i)_{i=0}^{n-1}$ is the coefficient vector, making $R \cong \mathbb{Z}^n$.
- $(x^n + 1)$ is an ideal, and elements $e(x) \in R$ map to elements in this lattice.
- The error $e(x)$ corresponds to a short vector (in the Euclidean norm) in the lattice, representing a small perturbation.
Ideal lattices inherit the ring’s structure, such as multiplication by polynomials.
Solving ring-LWE allows efficient recovery of short vectors in ideal lattices:
- Ring-LWE enables recovery of the secret $s(x)$, which corresponds to information about the underlying lattice structure.
- Decoding the noisy lattice point perturbed by $e(x)$ reveals a short vector.
The reduction shows that solving ring-LWE allows decoding perturbed lattice points for any ideal lattice in $R$, solving Ideal-SVP in the process.
Our goal is to introduce the simplest possible implementation of the ring-LWE encryption scheme.
- Choose a moderately large prime $p$ and large $n$ such that n|p-1
- $n$ should be a power of two and $512$ or above
- Example: $p = 12289$
Let $R_p := \mathbb{F}_p[x]/(x^n+1)$.
This is a finite ring with $p^n$ elements. It is not a finite field, as $x^n+1$ factors modulo $p$ (though it is irreducible over $\mathbb{Z}$).
The elements look like:
$$R_p = \{a_{n-1}x^{n-1} + a_{n-2}x^{n-2} + \ldots + a_1x + a_0: a_i \in \mathbb{F}_p\}$$
Public Setup
The public setup involves the following:
- A prime $p$ and dimension $n$ resulting in $R_p$
- A moderately large integer $k \in \mathbb{Z}$
- A notion of small, as applied to elements of $R_p$
These will be “ternary polynomials” with coefficients in ${-1,0,+1}$. The coefficients could also be drawn from a normal distribution centered at $0$ with some standard deviation.
Key Generation: Private/Public Keypair
Bob creates a private/public keypair as follows:
- Bob selects a small random element $s$ of $R_p$
- Bob selects a small random element $e_1$ of $R_p$
- Bob defines $(a, b = as + e_1) \in R_p \times R_p$
- The element $e_1$ can be discarded
- Bob keeps $s$ as his secret key
- Bob makes $(a,b)$ public as his public key
Encryption by Alice
Alice encrypts a message $m$ as follows:
- Select a small random $r \in R_p$ (ephemeral key)
- Select small random $e_2, e_3 \in R_p$
- Define $v = ar + e_2$, $w = br + e_3 + km$
- Alice may discard $k$, $e_2$, and $e_3$
- The ciphertext is $(v, w)$, which is sent to Bob
Decryption by Bob
Bob decrypts the message:
- Compute $x = w – vs$
- Round $x$ to the nearest multiple of $k$
- The result should be an integer; divide it by $k$ to reveal the message $m$
Homomorphic Encryption
Homomorphic encryption allows computations to be performed on encrypted data without needing to decrypt it first. This enables privacy-preserving computations.
- Encryption: The data is encrypted using a homomorphic encryption scheme.
- Computation: Operations such as addition or multiplication are performed directly on the encrypted data.
- Decryption: The result of the computation is decrypted to reveal the final outcome.
If $enc(x)$ represents the encryption of data $x$, and $\oplus$ denotes addition on encrypted data, and $\otimes$ represents multiplication on encrypted data:
- $enc(x + y) = enc(x) \oplus enc(y)$
- $enc(x \times y) = enc(x) \otimes enc(y)$
Homomorphic encryption can be used in cloud computing, privacy-preserving machine learning, and secure multi-party computations.
Code Examples
code:
https://crates.io/crates/ring-lwe
Key generation:
pub fn keygen(params: &Parameters, seed: Option<u64>) -> ([Polynomial<i64>; 2], Polynomial<i64>) {
//rename parameters
let (n, q, f, omega) = (params.n, params.q, ¶ms.f, params.omega);
// Generate a public and secret key
let sk = gen_ternary_poly(n, seed);
let a = gen_uniform_poly(n, q, seed);
let e = gen_ternary_poly(n, seed);
let b = polyadd(&polymul_fast(&polyinv(&a,q), &sk, q, &f, omega), &polyinv(&e,q), q, &f); // b = -a*sk - e
// Return public key (b, a) as an array and secret key (sk)
([b, a], sk)
}
We generate the secret key, $a$, $e$ as random polynomials, ensuring $a$ is spread out and uniform whereas $sk$ and $e$ are “small” ternary polynomials. We then compute $b = -a*sk – e$, yielding the public key $[b,a]$ and secret key $sk$.
Encryption takes in a public key and plaintext polynomial and produces ciphertext:
pub fn encrypt(
pk: &[Polynomial<i64>; 2], // Public key (b, a)
m: &Polynomial<i64>, // Plaintext polynomial
params: &Parameters, //parameters (n,q,t,f)
seed: Option<u64> // Seed for random number generator
) -> [Polynomial<i64>; 2] {
let (n,q,t,f,omega) = (params.n, params.q, params.t, ¶ms.f, params.omega);
// Scale the plaintext polynomial. use floor(m*q/t) rather than floor (q/t)*m
let scaled_m = mod_coeffs(m * q / t, q);
// Generate random polynomials
let e1 = gen_ternary_poly(n, seed);
let e2 = gen_ternary_poly(n, seed);
let u = gen_ternary_poly(n, seed);
// Compute ciphertext components
let ct0 = polyadd(&polyadd(&polymul_fast(&pk[0], &u, q, f, omega), &e1, q, f),&scaled_m,q,f);
let ct1 = polyadd(&polymul_fast(&pk[1], &u, q, f, omega), &e2, q, f);
[ct0, ct1]
}
We scale the plaintext polynomial via $\text{scaled\_m} = \lfloor q/t \rceil m$ and mod coefficients by $q$. Then generate random ternary polynomials $e_1$, $e_2$, $u$. Then $ct_0 = pk[0]*u+e_1+\text{scaled\_m}$ and $ct_1 = pk[1]*u + e_2$, and the final ciphertext is the pair $[ct_0,ct_1]$.
Finally, decryption:
pub fn decrypt(
sk: &Polynomial<i64>, // Secret key
ct: &[Polynomial<i64>; 2], // Array of ciphertext polynomials
params: &Parameters
) -> Polynomial<i64> {
let (_n,q,t,f,omega) = (params.n, params.q, params.t, ¶ms.f, params.omega);
let scaled\_pt = polyadd(&polymul_fast(&ct[1], sk, q, f, omega),&ct[0], q, f);
let mut decrypted_coeffs = vec![];
let mut s;
for c in scaled_pt.coeffs().iter() {
s = nearest_int(c*t,q);
decrypted_coeffs.push(s.rem_euclid(t));
}
Polynomial::new(decrypted_coeffs)
}
We compute $\text{scaled\_pt} = ct[1]*sk + ct[0]$, then for each coefficient $c$ in $\text{scaled\_pt}$ compute $\lfloor ct/q \rceil$ and take the remainder modulo $t$. The polynomial of coefficients is the decrypted message.
Keygen/encrypt/decrypt from start to finish:
let seed = None; //set the random seed
let message = String::from("hello");
let params = Parameters::default();
let keypair = keygen_string(¶ms,seed);
let pk_string = keypair.get("public").unwrap();
let sk_string = keypair.get("secret").unwrap();
let ciphertext_string = encrypt_string(&pk_string, &message, ¶ms,seed);
let decrypted_message = decrypt_string(&sk_string, &ciphertext_string, ¶ms);
assert_eq!(message, decrypted_message, "test failed: {} != {}", message, decrypted_message);
We use serialization and base64 encoding to compress the output strings.
For the homomorphic encryption, we only achieve a single product, so this is “leveled homomorphic encryption” at level one for the time being. We use a form of relinearization described here:
We perform multiplications of the ciphertext polynomials and the divide by $\Delta = q/t$. The implementation is as follows:
let seed = None; //set the random seed
let mut params = Parameters::default();
let (q, t, f) = (params.q, params.t, ¶ms.f);
params.q = q*q;
params.omega = omega(params.q, 2*params.n);
//create polynomials from ints
let m0_poly = Polynomial::new(vec![1, 0, 1]);
let m1_poly = Polynomial::new(vec![0, 0, 1]);
// Generate the keypair
let (pk, sk) = keygen(¶ms,seed);
// Encrypt plaintext messages
let u = encrypt(&pk, &m0_poly, ¶ms, seed);
let v = encrypt(&pk, &m1_poly, ¶ms, seed);
let plaintext_prod = polymul(&m0_poly, &m1_poly, t, &f);
//compute product of encrypted data, using non-standard multiplication
let c0 = polymul(&u[0],&v[0],params.q,&f);
let u0v1 = &polymul(&u[0],&v[1],params.q,&f);
let u1v0 = &polymul(&u[1],&v[0],params.q,&f);
let c1 = polyadd(u0v1,u1v0,params.q,&f);
let c2 = polymul(&u[1],&v[1],params.q,&f);
//compute c0 + c1*s + c2*s*s
let c1_sk = &polymul(&c1,&sk,params.q,&f);
let c2_sk_squared = &polymul(&polymul(&c2,&sk,params.q,&f),&sk,params.q,&f);
let ciphertext_prod = polyadd(&polyadd(&c0,c1_sk,params.q,&f),c2_sk_squared,params.q,&f);
//let delta = q / t, divide coeffs by 1 / delta^2
let delta = q / t;
let decrypted_prod = mod_coeffs(Polynomial::new(ciphertext_prod.coeffs().iter().map(|&coeff| nearest_int(coeff,delta * delta) ).collect::<Vec<_>>()),t);
assert_eq!(plaintext_prod, decrypted_prod, "test failed: {} != {}", plaintext_prod, decrypted_prod);
We’d eventually like to improve this to be fully homomorphic encryption.
module-lwe
- slides: module_lwe.pdf
- code: https://crates.io/crates/module-lwe
While the polynomial ring structure of ring-LWE is rich and useful for things like homomorphic encryption (since they’re based on rings, the structure is readily available), this additional algebraic structure is thought to make this system potentially vulnerable to attacks that exploit these number theoretic aspects.
There is a generalization of of ring-LWE called module-LWE which uses the rank $k$ free module $R_q^k$ instead of just the ring $R_q$ (when $k=1$), where again $R_q = \mathbb{Z}_q/(x^n+1)$ as in ring-LWE. The elements of $R_q^k$ are k-tuples of polynomials in $R_q$.
Module-LWE works sort of like a hybrid between the original LWE scheme and ring-LWE, combining both matrix operations and polynomial multiplication.
Advantages of module-LWE:
- Scalability: The main way to increase the security of ring-LWE is to increase the polynomial modulus degree $n$, but since this is alwayts a power of two there is no way to make a small increase in security if you are close to the necessary threshold. On the other hand, in module-LWE you can also increase the module rank $k$, which can be any nonnegative integer.
- Parallelization: Many of the computations in module-LWE involve matrix operations, which can be easily parallelized.
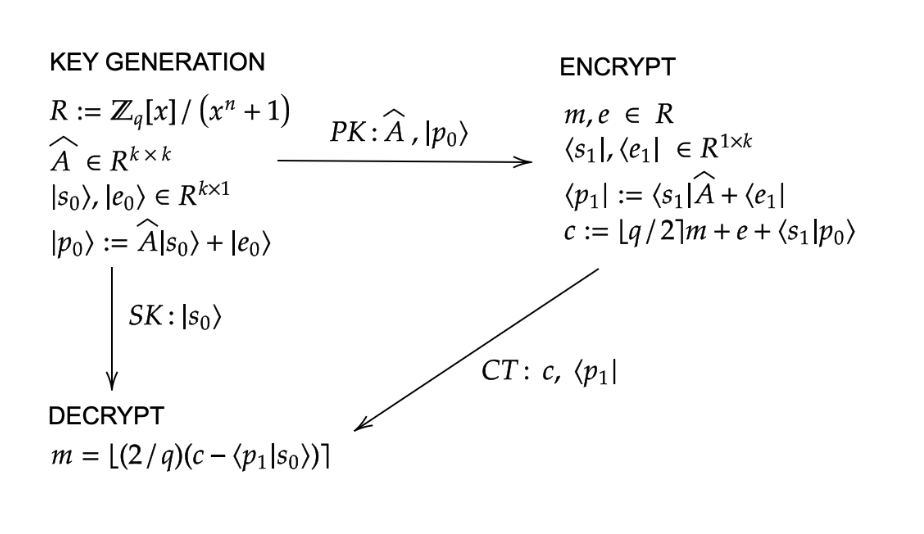
Public Setup
The public setup involves the following:
- A prime $q$ and modulus degree $n$ resulting in the ring $R_q$
- Module rank $k$
-
A notion of “small”, as applied to elements of $R_q^k$
- These are $k$-tuples of ternary polynomials, with coefficients in $\{-1,0,+1\}$
Key Generation
Bob selects a private/public keypair as follows:
- Bob selects a small random element $|s_0 \rangle$ of $R_q^{k+1}$
- Bob selects a small random element $|e_0 \rangle$ of $R_q^{k+1}$
- Bob selects a uniformly random matrix $\hat{A}$ in $R_q^{k \times k}$
- Bob defines $|p_0 \rangle := \hat{A}|s_0 \rangle + |e_0 \rangle$
The element $|e_0 \rangle$ can be discarded.
- Bob keeps $|s_0$ as his secret key
- Bob makes $(\hat{A},|p_0\rangle)$ public as his public key
Encryption by Alice
Alice encrypts a message $m \in \mathbb{Z}_2[x]/(x^n+1)$ as follows:
- Alice selects a small random element $\langle s_1 |$ of $R_q^{1 \times k}$ (ephemeral key)
- Alice selects small random $\langle e_1 | \in R_q^{1 \times k}$ and $e \in R_q$
- Alice defines $\langle p_1 | := \langle s_1 | \hat{A} + \langle e_1 |$ and $c := \lfloor q/2 \rceil m + e + \langle s_1 | p_0 \rangle$
Alice may discard $\langle s_1 |$, $\langle e_1 |$, and $e$
- The ciphertext is $(c, \langle p_1 |)$, which is sent to Bob
Decryption by Bob
Bob decrypts the message as follows:
- Compute $x = c – \langle p_1 | s_0 \rangle$
- Divide by $\lfloor q/2 \rceil$
- Round the coefficients to the nearest integer modulo $2$
- the result is the message $m$
Correctness
$x = c – \langle p_1 | s_0 \rangle$
$= (\lfloor q/2 \rceil m + e + \langle s_1 | p_0 \rangle ) – (\langle s_1 | \hat{A} + \langle e_1 |)|s_0 \rangle$
$= \lfloor q/2 \rceil m + e + \langle s_1 | \hat{A} | s_0 \rangle + \langle s_1 | e_0 \rangle – \langle s_1 | \hat{A} | s_0 \rangle + \langle e_1 | s_0 \rangle$
$= \lfloor q/2 \rceil m + \text{small polynomials}$
so dividing by $\lfloor q/2 \rceil$ and rounding coefficients to the nearest integer modulo $2$ returns $m$.
Code Examples
We’ve published our Rust implementation as a crate at https://crates.io/crates/module-lwe.
The key generation is fairly straightforward:
pub fn keygen(
params: &Parameters,
seed: Option<u64> //random seed
) -> ((Vec<Vec<Polynomial<i64>>>, Vec<Polynomial<i64>>), Vec<Polynomial<i64>>) {
let (n,q,k,f,omega) = (params.n, params.q, params.k, ¶ms.f, params.omega);
//Generate a public and secret key
let a = gen_uniform_matrix(n, k, q, seed);
let sk = gen_small_vector(n, k, seed);
let e = gen_small_vector(n, k, seed);
let t = add_vec(&mul_mat_vec_simple(&a, &sk, q, &f, omega), &e, q, &f);
//Return public key (a, t) and secret key (sk) as a 2-tuple
((a, t), sk)
}
We essentially generate a uniformly random matrix with coefficients in $R_q$, generate the secret key and small error vector, compute $t$, and this gives the public and private keys.
Encryption is also rather brief:
pub fn encrypt(
a: &Vec<Vec<Polynomial<i64>>>,
t: &Vec<Polynomial<i64>>,
m_b: &Vec<i64>,
params: &Parameters,
seed: Option<u64>
) -> (Vec<Polynomial<i64>>, Polynomial<i64>) {
//get parameters
let (n, q, k, f, omega) = (params.n, params.q, params.k, ¶ms.f, params.omega);
//generate random ephermal keys
let r = gen_small_vector(n, k, seed);
let e1 = gen_small_vector(n, k, seed);
let e2 = gen_small_vector(n, 1, seed)[0].clone(); // Single polynomial
//compute nearest integer to q/2
let half_q = nearest_int(q,2);
// Convert binary message to polynomial
let m = Polynomial::new(vec![half_q])*Polynomial::new(m_b.to_vec());
// Compute u = a^T * r + e_1 mod q
let u = add_vec(&mul_mat_vec_simple(&transpose(a), &r, q, f, omega), &e1, q, f);
// Compute v = t * r + e_2 - m mod q
let v = polysub(&polyadd(&mul_vec_simple(t, &r, q, &f, omega), &e2, q, f), &m, q, f);
(u, v)
}
We generate random ephemeral keys as small error vectors again with coefficients in $R_q$, compute $\lfloor q/2 \rceil$, convert the binary message to a polynomial with $\{0,1\}$ coefficients, then compute the vector $u$ and polynomial $v$. The ciphertext is $(u,v)$.
Finally, decrypt gives the plaintext message given the ciphertext and secret keys:
pub fn decrypt(
sk: &Vec<Polynomial<i64>>, //secret key
u: &Vec<Polynomial<i64>>, //ciphertext vector
v: &Polynomial<i64> , //ciphertext polynomial
params: &Parameters
) -> Vec<i64> {
let (q, f, omega) = (params.q, ¶ms.f, params.omega); //get parameters
let scaled_pt = polysub(&v, &mul_vec_simple(&sk, &u, q, &f, omega), q, f); //Compute v-sk*u mod q
let half_q = nearest_int(q,2); // compute nearest integer to q/2
let mut decrypted_coeffs = vec![];
let mut s;
for c in scaled_pt.coeffs().iter() {
s = nearest_int(*c,half_q).rem_euclid(2);
decrypted_coeffs.push(s);
}
decrypted_coeffs
}
We compute $v – sk*u$, a polynomial, then again compute $\lfloor q/2 \rceil$, and then compute $c / \lfloor q/2 \rceil \text{ mod } 2$ for each coefficient $c$. This yields the decrypted message.
Note that module-lwe is not fully homomorphic, but it is additively homomorphic.
let seed = None; //set the random seed
let params = Parameters::default();
let (n, q, f) = (params.n, params.q, ¶ms.f);
let mut m0 = vec![1, 0, 1];
m0.resize(n, 0);
let mut m1 = vec![0, 0, 1];
m1.resize(n, 0);
let mut plaintext_sum = vec![1, 0, 0];
plaintext_sum.resize(n, 0);
let (pk, sk) = keygen(¶ms,seed);
// Encrypt plaintext messages
let u = encrypt(&pk.0, &pk.1, &m0, ¶ms, seed);
let v = encrypt(&pk.0, &pk.1, &m1, ¶ms, seed);
// Compute sum of encrypted data
let ciphertext_sum = (add_vec(&u.0,&v.0,q,f), polyadd(&u.1,&v.1,q,f));
// Decrypt ciphertext sum u+v
let mut decrypted_sum = decrypt(&sk, &ciphertext_sum.0, &ciphertext_sum.1, ¶ms);
decrypted_sum.resize(n, 0);
assert_eq!(decrypted_sum, plaintext_sum, "test failed: {:?} != {:?}", decrypted_sum, plaintext_sum);
That is, if we encrypt $u$, $v$ to get $enc(u)$ and $enc(v)$, then form the sum $enc(u)+enc(v)$, we have $dec(enc(u)+enc(v)) = u+v$, so we recover the original sum.
We use a serialization and base64 encoding on the resulting arrays of ints to store the keys in a compact form.
Here is the entire encryption process from start to finish:
let seed = None; //set random seed
let message = String::from("hello");
let params = Parameters::default();
let keypair = keygen_string(¶ms,seed);
let pk_string = keypair.get("public").unwrap();
let sk_string = keypair.get("secret").unwrap();
let ciphertext_string = encrypt_string(&pk_string, &message, ¶ms,seed);
let decrypted_message = decrypt_string(&sk_string, &ciphertext_string, ¶ms);
assert_eq!(message, decrypted_message, "test failed: {} != {}", message, decrypted_message);
Note here we use the string methods which generate the keys, ciphertext, and message as a string.
the number theoretic transform (NTT)
In both of the above schemes, we perform a certain number of polynomial multiplications. There is a way to significantly speed this operation up from $\mathcal{O}(n^2)$ to $\mathcal{O}(n\log(n))$.
Polynomials have the property that their multiplication can be viewed as a cyclic convolution of the coefficients. That is, polynomial multiplication is just $f \star g$.
In general, the Fourier transform will take a convolution of functions to a pointwise product, so that $\mathcal{F}(f \star g) = \mathcal{F}(f) \cdot \mathcal{F}(g)$.
We can then perform multiplication in the original domain by performing an inverse Fourier transform, that is:
$f \star g = \mathcal{F}^{-1}(\mathcal{F}(f) \cdot \mathcal{F}(g))$
Since we are working over the discrete ring $\mathbb{Z}_q[x]/(x^n+1)$, we instead use a version of the NTT which is exact and takes arrays of integers to arrays of integers. This is called the “number theoretic transform”, and relies on a root of unity in the given coefficient ring.
In $\mathbb{Z}_q$, the roots of unity are given by examining the multiplicative group $(\mathbb{Z}_q)^{\times}$, which is just a cyclic group of order $q-1$ if $q$ is prime. Generally, the size of the group is $\varphi(q)$, the Euler totient function, and will have cyclic factors of size $\varphi(p_i^{k_i})$ for each prime factor $p_i$ of $q$. It is only cyclic when $q=2, 4, p^k, 2p^k$ which is the case we’ll focus on, in particular $p^k$.
Thus, to find an $n^{th}$ root of unity, we need that $n \mid \varphi(q)$. If we then have a primitive root of unity $g$, an element which generates the entire multiplicative group $(\mathbb{Z}_q)^{\times}$, then $\omega = g^{\varphi(q)/n}$ will be an $n^{th}$ root of unity. Again, $\omega$ is just an integer modulo $q$.
The NTT is then just:
$\hat{a}_k = \sum_{j=0}^{n-1} a_j \omega^{jk} \text{ mod } q \quad \text{for } k=0, \ldots, n-1$
One can think of this as the discrete Fourier transform with a different root of unity. This operation can be represented by a matrix.
In order to optimize this operation, we use the Cooley–Tukey method which uses butterfly operations recursively split the arrays in half. This is a reason that $n$ must be a power of $2$.
pub fn ntt(a: &[i64], omega: i64, n: usize, p: i64) -> Vec<i64> {
let mut result = a.to_vec();
let mut step = n/2;
while step > 0 {
let w_i = mod_exp(omega, (n/(2*step)).try_into().unwrap(), p);
for i in (0..n).step_by(2*step) {
let mut w = 1;
for j in 0..step {
let u = result[i+j];
let v = result[i+j+step];
result[i+j] = mod_add(u,v,p);
result[i+j+step] = mod_mul(mod_add(u,p-v,p),w,p);
w = mod_mul(w,w_i,p);
}
}
step/=2;
}
result
}
n.b. If one needs an $n^{th}$ root of unity $\text{mod } N$ and $N$ is composite, It’s possible to find an $n^{th}$ root of unity $\omega_i$ for each cyclic factor of size $\varphi(p_i^{k_i})$ as long as $n \mid \varphi(p_i^{k_i})$ for each $i$. Then one can use the Chinese remainder theorem isomorphism to pull back each $\omega_i$ to get a root of unity $\omega$ which satisfies the necessary properties, namely $\sum_{j=0}^{n-1} \omega^{jk} = 0$ for $1 \le k < n$.
module-lattice key encapsulation mechanism (ML-KEM), FIPS 203, Kyber
code:
https://crates.io/crates/mlkem-fips203
FIPS 203 paper:
https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.203.pdf
Kyber paper:
https://eprint.iacr.org/2017/634.pdf
While both ring-LWE and module-LWE represent post-quantum, lattice-based cryptosystems, neither of them have been directly standardized yet. Ring-LWE is more useful for homomorphic encryption, with the potential future security vulnerabilities arising from the direct algebraic ring structure. Module-LWE is more useful as an internal component of what is called a key encapsulation mechanism, which is a way to generate a shared key K, and encrypt the key itself to get a ciphertext version cwhich can be transmitted over an insecure channel. This is meant to be used in conjunction with another symmetric key cryptosystem, for instance AES which was standardized by NIST in FIPS PUB 197 on Nov. 26, 2001.
For our implementation, we initially made use of our module-lwe implementation but then decided to follow closely Giacomo Pope’s implementation in Python, kyber-py:
https://github.com/giacomopope/kyber-py
The end goal will be to create the key encapsulation mechanism, which generates a public key pk and secret key sk, encapsulates pkto get the shared key K and ciphertext c, then use the secret key sk to decapsulate c to obtain the shared key K.
We need to be careful about how we generate randomness. We use a DRBG (deterministic random bit generator) to generate a stream of random bytes if the seed is set, and otherwise use OS/system randomness via getrandom.
use aes_ctr_drbg::DrbgCtx;
...
/// Set the DRBG to be used for random bytes
pub fn set_drbg_seed(&mut self, seed: Vec<u8>) {
let p = vec![48, 0]; // personalization string must be min. 48 bytes long
let mut drbg = DrbgCtx::new(); // instantiate the DRBG
drbg.init(&seed, p); // initialize the DRBG with the seed
self.drbg = Some(drbg); // Store the DRBG in the struct
}
...
fn gen_random_bytes(size: usize, drbg: Option<&mut DrbgCtx>) -> Vec<u8> {
let mut out = vec![0; size];
if let Some(drbg) = drbg {
drbg.get_random(&mut out);
}
else {
getrandom(&mut out).expect("Failed to get random bytes");
}
out
}
We use two psuedorandom functions, prf_2 and prf_3, one for each value of eta=2 or eta=3, where the size of Shake256 hash is either 128 or 192 bytes, respectively.
pub fn prf_2(s: Vec<u8>, b: u8) -> Vec<u8> {
// Concatenate s and b
let mut m = s;
m.push(b);
// Apply shake_256 hash
let mut shake_256hasher = Shake256Hasher::<128>::default();
shake_256hasher.write(&m);
let bytes_result = HasherContext::finish(&mut shake_256hasher);
bytes_result[0..].to_vec()
}
pub fn prf_3(s: Vec<u8>, b: u8) -> Vec<u8> {
// Concatenate s and b
let mut m = s;
m.push(b);
// Apply shake_256 hash
let mut shake_256hasher = Shake256Hasher::<192>::default();
shake_256hasher.write(&m);
let bytes_result = HasherContext::finish(&mut shake_256hasher);
bytes_result[0..].to_vec()
}
eta is a parameter related to the width of a CBD (centered binomial distribution), which is given as follows:
$X = \sum_{i=1}^{\eta} (a_i – b_i), \quad \text{where } a_i, b_i \sim \text{Ber}(1/2)$
This allows us to generate random polynomials.
pub fn cbd(input_bytes: Vec<u8>, eta: usize, n:usize) -> Polynomial<i64> {
assert_eq!(eta*n/4, input_bytes.len(), "input length must be eta*n/4");
let mut coefficients = vec![0;n];
let mut t = BigUint::from_bytes_le(&input_bytes);
let mask = BigUint::from((1 << eta)-1 as u64);
let mask2 = BigUint::from((1 << 2*eta)-1 as u64);
for i in 0..n {
let x = t.clone() & mask2.clone();
let a = (x.clone() & mask.clone()).count_ones() as i64;
let b = ((x.clone() >> eta) & mask.clone()).count_ones() as i64;
t >>= 2*eta;
coefficients[i] = a-b;
}
Polynomial::new(coefficients)
}
We also use an extendable output function (XOF) to extend a random 32 byte input given two domain separation parameters to get an 840 byte random output:
pub fn xof(bytes32: Vec<u8>, i: u8, j: u8) -> Vec<u8> {
// Concatenate bytes32, i, and j
let mut m = bytes32;
m.push(i);
m.push(j);
// Apply shake_128 hash
let mut shake_128hasher = Shake128Hasher::<840>::default();
shake_128hasher.write(&m);
let bytes_result = HasherContext::finish(&mut shake_128hasher);
bytes_result[0..].to_vec()
}
This is used to generate a random matrix from a seed. Note this is essentially the matrix from module-lwe, and is a random k x k matrix whose coefficients are polynomials in the ring $R_q$. In this case, we are setting q=3329 as a global parameter, a prime, noting that $\mathbb{Z}_q$ is a field.
pub fn generate_matrix_from_seed(
rho: Vec<u8>,
rank: usize,
n: usize,
transpose: bool,
) -> Vec<Vec<Polynomial<i64>>> {
let mut a_data = vec![vec![Polynomial::new(vec![]); rank]; rank];
for i in 0..rank {
for j in 0..rank {
let xof_bytes = xof(rho.clone(), j as u8, i as u8);
a_data[i][j] = Polynomial::new(ntt_sample(xof_bytes, n));
}
}
if transpose {
matrix_transpose(a_data)
} else {
a_data
}
}
Note that again we are using the Polynomial<i64> type because it is convenient, but it would make a lot of sense to implement this as a struct with the methods we need for polyadd, polysub, etc. We instead just opt to keep everything as utility functions for now.
We can use the prf functions to generate an error vector as well:
pub fn generate_error_vector(
sigma: Vec<u8>,
eta: usize,
b: u8,
k: usize,
poly_size: usize,
) -> (Vec<Polynomial<i64>>, u8) {
let mut elements = vec![Polynomial::new(vec![]); k];
let mut current_b = b;
for i in 0..k {
let prf_output: Vec<u8>;
if eta == 2 {
prf_output = prf_2(sigma.clone(), current_b);
} else if eta == 3 {
prf_output = prf_3(sigma.clone(), current_b);
} else {
panic!("eta must be 2 or 3"); // Handle invalid eta values
}
assert_eq!(eta*poly_size/4, prf_output.len(), "eta*poly_size/4 must be 128 or 192 (prf output length)");
elements[i] = cbd(prf_output, eta, poly_size);
current_b += 1;
}
(elements, current_b)
}
Similarly we can generate a random polynomial using the cbd function:
pub fn generate_polynomial(
sigma: Vec<u8>,
eta: usize,
b: u8,
poly_size: usize,
q: Option<i64>,
) -> (Polynomial<i64>, u8) {
// get the prf_output depending on eta = 2, or eta = 3
let prf_output: Vec<u8>;
if eta == 2 {
prf_output = prf_2(sigma, b);
} else if eta == 3 {
prf_output = prf_3(sigma, b);
} else {
panic!("eta must be 2 or 3"); // Handle invalid eta values
}
let poly = cbd(prf_output, eta, poly_size); // form the polynomial array from a centered binomial dist.
//if a modulus is set, place coeffs in [0,q-1]
if let Some(q) = q {
return (mod_coeffs(poly,q), b + 1);
}
(poly, b + 1)
}
Now that we’re able to generate random polynomials, error vectors, and matrices, we want to be able to compress/encode and decompress/decode our inputs and outputs.
To compress a polynomial, we compress its coefficients using this function:
fn compress_ele(x: i64, d: usize) -> i64 {
let t = 1 << d;
let y = (t * x.rem_euclid(3329) + 1664) / 3329; // n.b. 1664 = 3329 / 2
y % t
}
To encode a polynomial, we use a bit-width parameter
d
which is usually 12 or 1:
pub fn encode_poly(poly: Polynomial<i64>, d: usize) -> Vec<u8> {
let poly_mod = mod_coeffs(poly.clone(), 3329);
let mut t = BigUint::zero(); // Start with a BigUint initialized to zero
let mut coeffs = poly_mod.coeffs().to_vec(); // get the coefficients of the polynomial
coeffs.resize(256, 0); // ensure they're the right size
for i in 0..255 {
// OR the current coefficient then left shift by d bits
t |= BigUint::from(coeffs[256 - i - 1] as u64); // Use BigUint for coefficients
t <<= d; // Equivalent to t = t * 2^d
}
// Add the last coefficient
t |= BigUint::from(coeffs[0] as u64);
// Convert BigUint to a byte vector
let byte_len = 32 * d;
let mut result = t.to_bytes_le(); // Convert to little-endian bytes
result.resize(byte_len, 0); // Ensure the result is exactly `32 * d` bytes
result
}
Decode and decompress invert this. For vectors of polynomials, we just compress each polynomial, encode each polynomial, and extend the array of bytes.
The final important step before describing the actual PKE and encapsulation algorithms is the NTT. Above, we saw that the NTT depended on an $n^{th}$ root of unity. In this case, the other global Kyber parameter is n=256, which is the degree of the polynomials. Since $q=3329$, and since Cooley-Tukey requires a $2n^{th}$ root of unity (a square root of an $n^{th}$ root of unity), this would mean a $512^{th}$ root of unity, which doesn’t exist in $\mathbb{Z}_q$ since $512 \nmid 3328$. Therefore we need to do something different.
Indeed, the FIPS 203 paper outlines on pg. 24 how to perform an NTT despite this limitation. It uses the Chinese remainder theorem to write the ring $R_q = \mathbb{Z}_q[x]/(x^{256}+1)$ as
$T_q = \bigoplus_{i=0}^{127}\mathbb{Z}_q[x]/(x^2 – \zeta^{BitRev_7(i)+1})$
which is a sum of $128$ quadratic terms. This isomorphism means we only need a $256^{th}$ root of unity, which we do have. We just need to compute the bit reversal function, and the $\zeta$’s:
pub fn bit_reverse(i: i64, k: usize) -> i64 {
let mut reversed = 0;
let mut n = i;
for _ in 0..k {
reversed = (reversed << 1) | (n & 1);
n >>= 1;
}
reversed
}
...
let zetas: Vec<i64> = (0..128)
.map(|i| mod_exp(17, bit_reverse(i, 7), 3329))
.collect();
Here mod_exp is just the modular exponentiation modulo q.
The NTT is similar to the usual butterfly operations, but we pair coefficients:
pub fn poly_ntt(poly: Polynomial<i64>, zetas: Vec<i64>) -> Polynomial<i64> {
let mut coeffs = poly.coeffs().to_vec(); // Convert slice to Vec<i64>
coeffs.resize(256, 0); // Ensure uniform length
let mut k = 1;
let mut l = 128;
while l >= 2 {
let mut start = 0;
while start < 256 {
let zeta = zetas[k];
k += 1;
for j in start..start+l {
let t = zeta*coeffs[j+l];
coeffs[j+l] = (coeffs[j]-t).rem_euclid(3329);
coeffs[j] = (coeffs[j]+t).rem_euclid(3329);
}
start += 2*l;
}
l >>= 1;
}
Polynomial::new(coeffs)
}
With this NTT (and its associated inverse), we can define the ntt for vectors as well by just operating on each coefficient. Since we will deal with polynomials and vectors in their NTT form, we multiply them pointwise, and so we need to carefully define the multiplication in $T_q$:
pub fn ntt_base_multiplication(a0:i64 , a1:i64, b0:i64, b1:i64, zeta:i64) -> (i64, i64) {
let r0 = (a0*b0+zeta*a1*b1).rem_euclid(3329);
let r1 = (a1*b0+a0*b1).rem_euclid(3329);
(r0, r1)
}
pub fn ntt_coefficient_multiplication(f_coeffs: Vec<i64>, g_coeffs: Vec<i64>, zetas: Vec<i64>) -> Vec<i64> {
let mut new_coeffs = vec![];
// Multiply in each of the 128 Z_q[x]/(x^2-zeta) factors
for i in 0..64 {
let (r0,r1) = ntt_base_multiplication(
f_coeffs[4*i+0],
f_coeffs[4*i+1],
g_coeffs[4*i+0],
g_coeffs[4*i+1],
zetas[64+i]);
let (r2,r3) = ntt_base_multiplication(
f_coeffs[4*i+2],
f_coeffs[4*i+3],
g_coeffs[4*i+2],
g_coeffs[4*i+3],
-zetas[64+i]);
new_coeffs.append(&mut vec![r0,r1,r2,r3]);
}
new_coeffs
}
With those definitions, we can define a dot product of vectors using this NTT multiplication:
pub fn mul_vec_simple(v0: Vec<Polynomial<i64>>, v1: Vec<Polynomial<i64>>, q: i64, f: Polynomial<i64>, zetas: Vec<i64>) -> Polynomial<i64> {
assert!(v0.len() == v1.len());
let mut result = Polynomial::new(vec![]);
for i in 0..v0.len() {
let v0_v1_mult = ntt_multiplication(v0[i].clone(), v1[i].clone(), zetas.clone());
result = polyadd(result, v0_v1_mult.clone(), q, f.clone());
}
mod_coeffs(result, q)
}
This allows us to then define multiplication of a matrix times a vector. Now we are ready to define the PKE and encapsulation operations.
We use different sets of parameters for different levels of security.
-
MLKEM512 (~128 bit security):
k=2,eta_1=3,eta_2=2,du=10,dv=4 -
MLKEM768 (~192 bit security):
k=3,eta_1=2,eta_2=2,du=10,dv=4 -
MLKEM1024 (~256 bit security):
k=4,eta_1=2,eta_2=2,du=11,dv=5
We keep these in parameters::Parameters.
The PKE keygen follows Algorithm 13 of FIPS 203:
pub fn _k_pke_keygen(
&self,
d: Vec<u8>,
) -> (Vec<u8>, Vec<u8>) {
// Expand 32 + 1 bytes to two 32-byte seeds.
// Note: rho, sigma are generated using hash_g
let (rho, sigma) = hash_g([d.clone(), vec![self.params.k as u8]].concat());
// Generate A_hat from seed rho
let a_hat = generate_matrix_from_seed(rho.clone(), self.params.k, self.params.n, false);
// Set counter for PRF
let prf_count = 0;
// Generate the error vectors s and e
let (s, _prf_count) = generate_error_vector(sigma.clone(), self.params.eta_1, prf_count, self.params.k, self.params.n);
let (e, _prf_count) = generate_error_vector(sigma.clone(), self.params.eta_1, prf_count, self.params.k, self.params.n);
// the NTT of s as an element of a rank k module over the polynomial ring
let s_hat = vec_ntt(s, self.params.zetas.clone());
// the NTT of e as an element of a rank k module over the polynomial ring
let e_hat = vec_ntt(e, self.params.zetas.clone());
// A_hat @ s_hat + e_hat
let a_hat_s_hat = mul_mat_vec_simple(a_hat, s_hat.clone(), self.params.q, self.params.f.clone(), self.params.zetas.clone());
let t_hat = add_vec(a_hat_s_hat, e_hat, self.params.q, self.params.f.clone());
// Encode the keys
let mut ek_pke = encode_vector(t_hat, 12); // Encoding vec of polynomials to bytes
ek_pke.extend(rho); // append rho, output of hash function
let dk_pke = encode_vector(s_hat, 12); // Encoding s_hat for dk_pke
(ek_pke, dk_pke)
}
Note that this essentially computes $\hat{t}=\hat{A}\hat{s} + \hat{e}$ and encodes this vector to get the public key, and then just encodes $\hat{s}$ to get the private key.
Next, the PKE encryption:
pub fn _k_pke_encrypt(
&self,
ek_pke: Vec<u8>,
m: Vec<u8>,
r: Vec<u8>,
) -> Result<Vec<u8>, String> {
let expected_len = ek_pke.len();
let received_len = 384 * self.params.k + 32;
if expected_len != received_len {
return Err(format!(
"Type check failed: ek_pke length mismatch (expected {}, got {})",
received_len, expected_len
));
}
// Unpack ek
let (t_hat_bytes_slice, rho_slice) = ek_pke.split_at(ek_pke.len() - 32);
let t_hat_bytes = t_hat_bytes_slice.to_vec();
let rho = rho_slice.to_vec();
// decode the vector of polynomials from bytes
let t_hat = decode_vector(t_hat_bytes.clone(), self.params.k, 12);
// check that t_hat has been canonically encoded
if encode_vector(t_hat.clone(),12) != t_hat_bytes {
return Err("Modulus check failed: t_hat does not encode correctly".to_string());
}
// Generate A_hat^T from seed rho
let a_hat_t = generate_matrix_from_seed(rho.clone(), self.params.k, self.params.n, true);
// generate error vectors y, e1 and error polynomial e2
let prf_count = 0;
let (y, _prf_count) = generate_error_vector(r.clone(), self.params.eta_1, prf_count, self.params.k, self.params.n);
let (e1, _prf_count) = generate_error_vector(r.clone(), self.params.eta_2, prf_count, self.params.k, self.params.n);
let (e2, _prf_count) = generate_polynomial(r.clone(), self.params.eta_2, prf_count, self.params.n, None);
// compute the NTT of the error vector y
let y_hat = vec_ntt(y, self.params.zetas.clone());
// compute u = intt(a_hat.T * y_hat) + e1
let a_hat_t_y_hat = mul_mat_vec_simple(a_hat_t, y_hat.clone(), self.params.q, self.params.f.clone(), self.params.zetas.clone());
let a_hat_t_y_hat_intt = vec_intt(a_hat_t_y_hat, self.params.zetas.clone());
let u = add_vec(a_hat_t_y_hat_intt, e1, self.params.q, self.params.f.clone());
//decode the polynomial mu from the bytes m
let mu = decompress_poly(decode_poly(m, 1),1);
//compute v = intt(t_hat.y_hat) + e2 + mu
let t_hat_dot_y_hat = mul_vec_simple(t_hat, y_hat, self.params.q, self.params.f.clone(), self.params.zetas.clone());
let t_hat_dot_y_hat_intt = poly_intt(t_hat_dot_y_hat, self.params.zetas.clone());
let t_hat_dot_y_hat_intt_plus_e2 = polyadd(t_hat_dot_y_hat_intt.clone(), e2.clone(), self.params.q, self.params.f.clone());
let v = polyadd(t_hat_dot_y_hat_intt_plus_e2, mu, self.params.q, self.params.f.clone());
// compress vec u, poly v by compressing coeffs, then encode to bytes using params du, dv
let c1 = encode_vector(compress_vec(u,self.params.du),self.params.du);
let c2 = encode_poly(compress_poly(v,self.params.dv),self.params.dv);
//return c1 + c2, the concatenation of two encoded polynomials
Ok([c1, c2].concat())
}
We unpack $\hat{t}$ (and check correctness), then generate $\hat{A}^{T}$, generate error vectors $y$, $e_1$, and error polynomial $e_2$. Then we compute $\hat{y}$ (the NTT), and $u = intt(\hat{A}^T*\hat{y}) + e_1$ (a vector). We decode the message $m$ as $\mu$, then compute $v = intt(\hat{t}\cdot\hat{y}) + e_2 + \mu$ (a polynomials). We then compress vector $u$ and polynomial $v$ to get the ciphertext $c_1$, $c_2$.
Decryption is as follows:
pub fn _k_pke_decrypt(&self, dk_pke: Vec<u8>, c: Vec<u8> ) -> Vec<u8> {
// encoded size
let n = self.params.k * self.params.du * 32;
// break ciphertext into two encoded parts
let (c1, c2) = c.split_at(n);
let c1 = c1.to_vec();
let c2 = c2.to_vec();
// decode and decompress c1, c2, dk_pke into vector u, polynomial v, secret key
let u = decompress_vec(decode_vector(c1, self.params.k, self.params.du), self.params.du);
let v = decompress_poly(decode_poly(c2, self.params.dv), self.params.dv);
let s_hat = decode_vector(dk_pke, self.params.k, 12);
// compute u_hat, the NTT of u
let u_hat = vec_ntt(u, self.params.zetas.clone());
// compute w = v - (s_hat.u_hat).from_ntt()
let s_hat_dot_u_hat = mul_vec_simple(s_hat, u_hat, self.params.q, self.params.f.clone(), self.params.zetas.clone());
let s_hat_dot_u_hat_intt = poly_intt(s_hat_dot_u_hat, self.params.zetas.clone());
let w = polysub(v, s_hat_dot_u_hat_intt, self.params.q, self.params.f.clone());
// compress and encode w to get message m
let m = encode_poly(compress_poly(w,1),1);
m
}
We break the incoming ciphertext bytes into two parts, $c_1$, $c_2$. We then recover $u$, $v$, $\hat{s}$ from above. We compute the NTT $\hat{u}$. Finally we compute $w = v – (\hat{s} \cdot \hat{u})$, and compress and encode to get $m$.
That’s it! Here’s a full example of running the PKE to perform keygen/encrypt/decrypt. Keep in mind these are internal functions:
// run the basic PKE with a uniformly random message polynomial
let params = Parameters::mlkem512(); // initialize default parameters
let mut mlkem = MLKEM::new(params);
mlkem.set_drbg_seed(vec![0x42; 48]); // Example 48-byte seed
let d = (mlkem.params.random_bytes)(32, mlkem.drbg.as_mut());
let (ek_pke, dk_pke) = mlkem._k_pke_keygen(d); // Generate public and private keys for PKE
let rand_bytes_os = (mlkem.params.random_bytes)(mlkem.params.n, None); //get random bytes from OS
let rand_coeffs: Vec<i64> = rand_bytes_os.into_iter().map(|byte| byte as i64).collect(); // convert to i64 array
let m_poly = Polynomial::new(rand_coeffs); // create a polynomial from the random coefficients
let m = encode_poly(compress_poly(m_poly,1),1); // compress and encode the message polynomial
let r = vec![0x01, 0x02, 0x03, 0x04]; // Example random bytes for encryption
let c = match mlkem._k_pke_encrypt(ek_pke, m.clone(), r) { //perform encryption, handling potential errors
Ok(ciphertext) => ciphertext,
Err(e) => panic!("Encryption failed: {}", e),
};
let m_dec = mlkem._k_pke_decrypt(dk_pke, c); // perform the decryption
assert_eq!(m, m_dec); // check if the decrypted message matches the original message
There are three algorithms 16, 17, 18 for _keygen_internal, _encaps_internal, and _decaps_internal:
pub fn _keygen_internal(&self, d: Vec<u8>, z: Vec<u8>) -> (Vec<u8>, Vec<u8>) {
let (ek_pke, dk_pke) = self._k_pke_keygen(d);
let ek = ek_pke;
let dk = [dk_pke, ek.clone(), hash_h(ek.clone()), z].concat();
(ek, dk)
}
pub fn _encaps_internal(&self, ek: Vec<u8>, m: Vec<u8>) -> Result<(Vec<u8>, Vec<u8>), String> {
let (shared_k, r) = hash_g([m.clone(), hash_h(ek.clone())].concat());
let c = self._k_pke_encrypt(ek, m, r)?; // Propagate error with `?`
Ok((shared_k, c))
}
pub fn _decaps_internal(&self, dk: Vec<u8>, c: Vec<u8>) -> Result<Vec<u8>, String>{
// NOTE: ML-KEM requires input validation before returning the result of
// decapsulation. These are performed by the following three checks:
//
// 1) Ciphertext type check: the byte length of c must be correct
// 2) Decapsulation type check: the byte length of dk must be correct
// 3) Hash check: a hash of the internals of the dk must match
//
// Unlike encaps, these are easily performed in the kem decaps
if c.len() != 32 * (self.params.du * self.params.k + self.params.dv) {
return Err(format!(
"ciphertext type check failed. Expected {} bytes and obtained {}",
32 * (self.params.du * self.params.k + self.params.dv),
c.len()
));
}
if dk.len() != 768 * self.params.k + 96{
return Err(format!(
"decapsulation type check failed. Expected {} bytes and obtained {}",
768 * self.params.k + 96,
dk.len()
));
}
// Parse out data from dk as Vec<u8>
let dk_pke = dk[0..384 * self.params.k].to_vec();
let ek_pke = dk[384 * self.params.k..768 * self.params.k + 32].to_vec();
let h = dk[768 * self.params.k + 32..768 * self.params.k + 64].to_vec();
let z = dk[768 * self.params.k + 64..].to_vec();
// Ensure the hash-check passes
if hash_h(ek_pke.clone()) != h{
return Err("hash check failed".to_string());
}
// Decrypt the ciphertext
let m_prime = self._k_pke_decrypt(dk_pke, c.clone());
// Re-encrypt the recovered message
let (k_prime, r_prime) = hash_g([m_prime.clone(),h].concat());
let k_bar = hash_j([z,c.clone()].concat());
// Here the public encapsulation key is read from the private
// key and so we never expect this to fail the TypeCheck or ModulusCheck
let c_prime = match self._k_pke_encrypt(ek_pke.clone(), m_prime.clone(), r_prime.clone()) {
Ok(ciphertext) => ciphertext,
Err(e) => panic!("Encryption failed: {}", e),
};
// If c != c_prime, return K_bar as garbage
// WARNING: for proper implementations, it is absolutely
// vital that the selection between the key and garbage is
// performed in constant time
let shared_k = select_bytes(k_bar, k_prime, c == c_prime);
Ok(shared_k)
}
Note now this function may fail if the length is wrong for the ciphertext or secret key, in which case we return an error string.
Now for the final functions, the MLKEM keygen, encaps, decaps:
pub fn keygen(&mut self) -> (Vec<u8>, Vec<u8>) {
let d = (self.params.random_bytes)(32, self.drbg.as_mut());
let z = (self.params.random_bytes)(32, self.drbg.as_mut());
let (ek, dk) = self._keygen_internal(d,z);
return (ek, dk)
}
pub fn encaps(&mut self, ek: Vec<u8>) -> Result<(Vec<u8>, Vec<u8>), String> {
let m = (self.params.random_bytes)(32, self.drbg.as_mut());
let (shared_k, c) = self._encaps_internal(ek, m)?; // Propagate error with `?`
Ok((shared_k, c))
}
pub fn decaps(&self, dk: Vec<u8>, c: Vec<u8>) -> Result<Vec<u8>, String> {
let shared_k_prime = self._decaps_internal(dk, c)?; // Propagate error with `?`
Ok(shared_k_prime)
}
That’s it! We can perform the keygen/encaps/decaps as follows, which takes less than a millisecond on an M1 (2020) machine:
let params = Parameters::mlkem512();
let mut mlkem = MLKEM::new(params);
let (ek, dk) = mlkem.keygen();
let (shared_k,c) = match mlkem.encaps(ek) {
Ok(ciphertext) => ciphertext,
Err(e) => panic!("Encryption failed: {}", e),
};
let shared_k_decaps = match mlkem.decaps(dk,c) {
Ok(decapsulated_shared_key) => decapsulated_shared_key,
Err(e) => panic!("Decryption failed: {}", e),
};
assert_eq!(shared_k, shared_k_decaps);
n.b. None of this is written in constant-time, nor resistant to side-channel attacks, nor been audited for security. It’s simply meant to get people oriented to these new post-quantum cryptography systems, in a strongly-typed and fast language.
There are surely optimized and secure implementations. It sounds like OpenSSL is releasing their implementation tomorrow. I encourage you to head on over to the Bouncy Castle.